 Newsgroups Newsgroups |
Query | Metric | Quiz | About |
This site is about evaluation in information retrieval using the test corpus 20 newsgroups. You can find the data set(s) and more information at Jason Rennie's site. This site provides
In the last years similarity search has been becoming more promiment in the context of deep learning starting with Salakhutdinov and Hinton's paper on semantic hashing in 2007. This article also strikingly demonstrates the subtle intricacies and pitfalls in evaluation. It reports the precision at 100% recall for the RCV1-v2 corpus to be about 3%. Karol Grzegorczyk in his 2019 thesis Vector representations of text data in deep learning reports about 12%. A lower bound for precision at 100% recall is given when we have to retrieve all documents from the corpus to achieve 100% recall. This lower bound can be easily calculated (number of relevant documents divided by corpus size) and is independent from the applied similarity search algorithm:
1/N * sum_(i=1)^N rel(q_i)/N
where N is the size of the test corpus (equals number of similarity
queries) and rel(q_i) is the relevance for the i-th
similarity query.
Own calculations estimate that the lower bound is
much higher than 3% and they are consistent with Karol
Grzegorczyk's results. I am not documenting my RCV1-v2 evaluations here, because
Having said the above, my motivation for this site (20newsgroups.neurolab.de) is twofold.
When you look at the query results for document 1528211 "GP 2.0 vs. 2.2" you will notice that the first retrieved document Intel memory board for sale (doc id 7473806) has semantically not much similarity with the query document 981602. Why is that so?
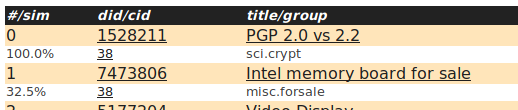
By looking at the respective message bodies we see that
This unsurprisingly leads us to the strong assumption, that removing boilerplate in the message from indexing would strongly improve retrieval performance.
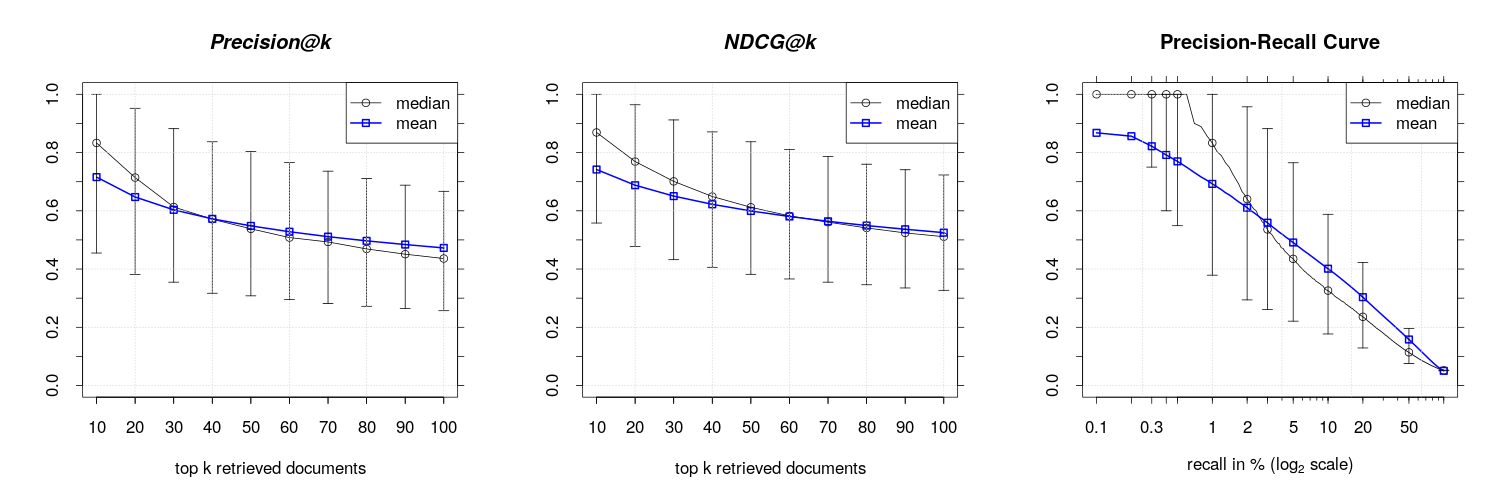
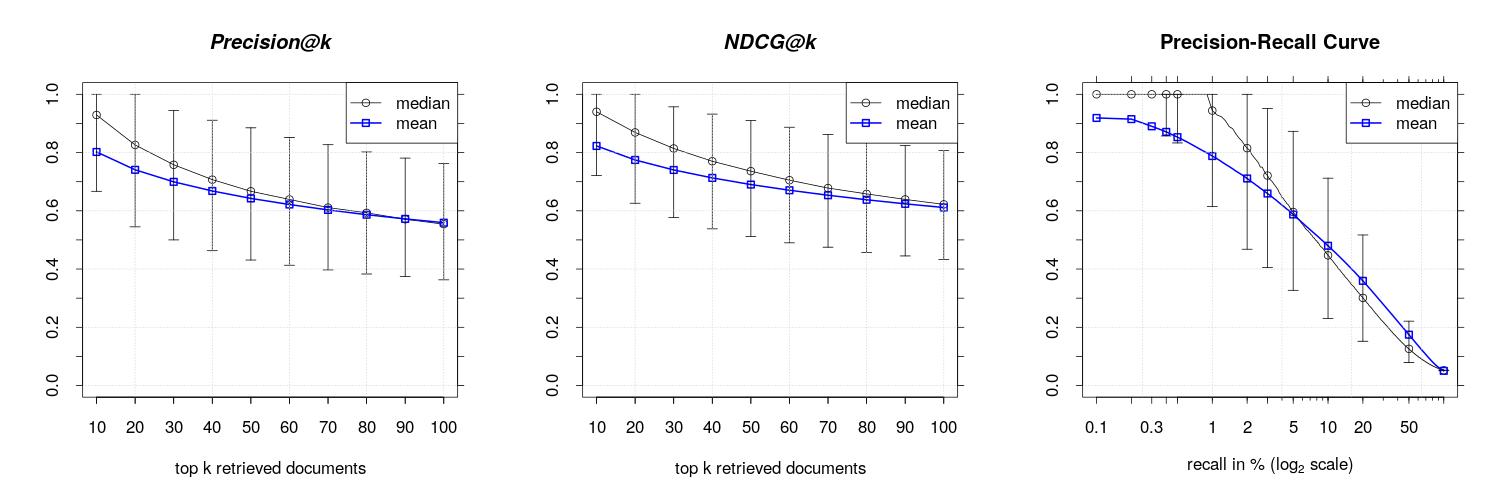
This hypothesis can also be experimentally confirmed. I created a second corpus where I removed the header lines in each news message and rerun the evaluation test. We observe an huge increase in precision and recall as can be seen in the below shown results for the single example document from above and also for corpus level results.
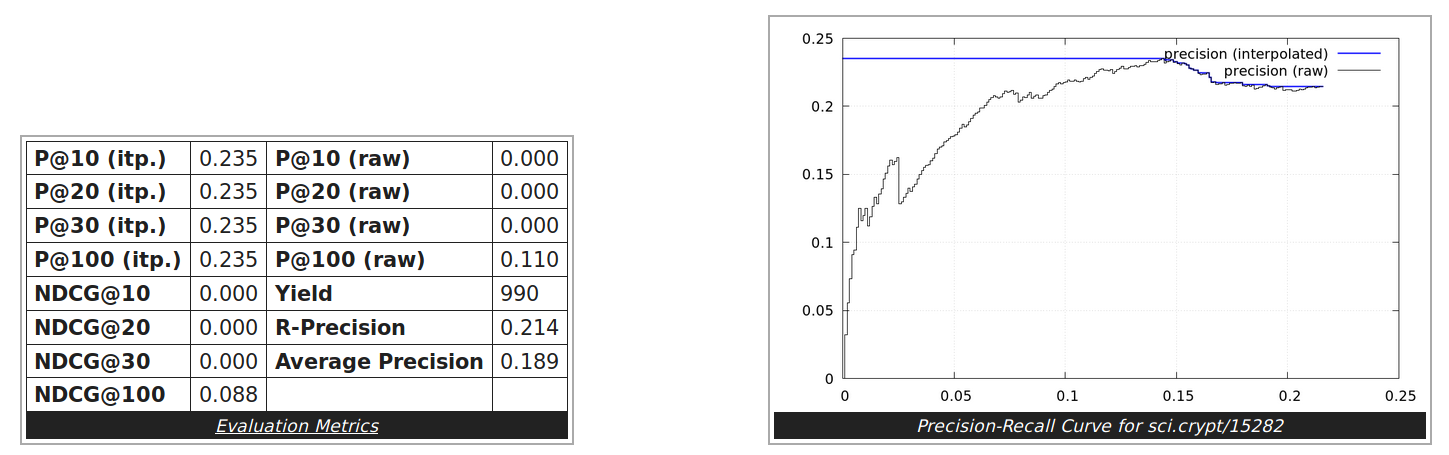
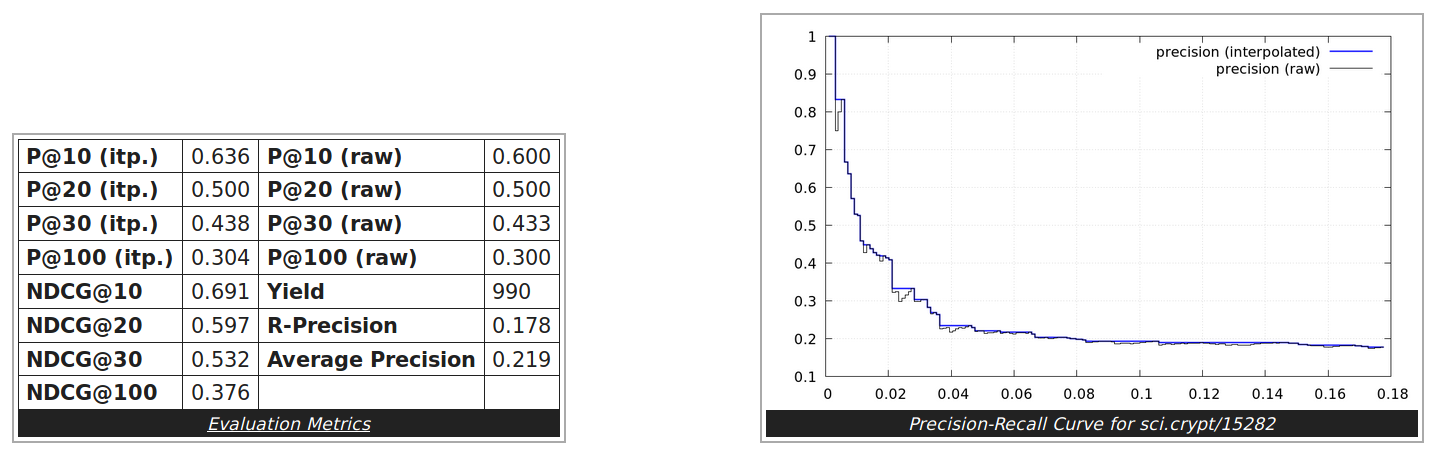
The 20 newsgroups test corpus is commonly used for evaluating text classification or similarity search tasks and has been collected by Ken Lang.
It consists of about 1000 articles from each of 20 Usenet newsgroups. Articles are from April 1993. For evaluation purposes the newsgroup name can be regarded as the category of a document. Here we concentrate on the bydate version consisting of 18846 documents (news messages) and does not include cross-posts (duplicates) and newsgroup-identifying headers (Xref, Newsgroups,Path, Followup-To, Date) compared to the original version (see Jason Rennie's 20 Newsgroups page.
In contrast to the also widely used evaluation corpora Reuters-21578 and more recently RCV1-v2 (see David Lewis' page for more information) the 20 Newsgroups test corpus is not protected by a NDA (non-disclosure agreement).
| ID | Group | Size |
|---|---|---|
| 0 | alt.atheism | 799 |
| 1 | comp.graphics | 973 |
| 2 | comp.os.ms-windows.misc | 985 |
| 3 | comp.sys.ibm.pc.hardware | 982 |
| 4 | comp.sys.mac.hardware | 963 |
| 5 | comp.windows.x | 988 |
| 6 | misc.forsale | 975 |
| 7 | rec.autos | 990 |
| 8 | rec.motorcycles | 996 |
| 9 | rec.sport.baseball | 994 |
| 10 | rec.sport.hockey | 999 |
| 11 | sci.crypt | 991 |
| 12 | sci.electronics | 984 |
| 13 | sci.med | 990 |
| 14 | sci.space | 987 |
| 15 | soc.religion.christian | 997 |
| 16 | talk.politics.guns | 910 |
| 17 | talk.politics.mideast | 940 |
| 18 | talk.politics.misc | 775 |
| 19 | talk.religion.misc | 628 |